今回はDeeplearning 4jを利用して画像認識を行う例として手書き文字を識別するプログラムを実装してみる。と言っても画像認識を行うニューラルネットワークの構築に関しては公式サイトのサンプルプログラム(
*1)を流用する。
プログラムは2つに分けて作成する。1つ目のプログラムでは画像認識を行うニューラルネットワークを構築・学習し、構築したニューラルネットワークをファイルに出力する。2つ目のプログラムではユーザによる数字を入力できるGUIを表示し、出力されたファイルをもとに再構築したニューラルネットワークで入力文字を識別する。実際の利用を考えても、このように学習と利用でプログラムを分けることはよくある構成と思われる。
■ プログラム1(画像認識ニューラルネットワークの構築・学習)
以下にDeepLearning 4jからMnistデータベースを取得し、手書き数字識別を行うニューラルネットワークを構築し、構築したニューラルネットワークをファイル出力するプログラムを示す。作成するニューラルネットワークの構成は下図のようになる。プログラム完了まで2時間程度はかかる。
図:構築するニューラルネットワークのイメージ
プログラム
import java.io.File;
import org.deeplearning4j.datasets.iterator.impl.MnistDataSetIterator;
import org.deeplearning4j.eval.Evaluation;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
//import org.deeplearning4j.nn.conf.LearningRatePolicy;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.conf.layers.setup.ConvolutionLayerSetup;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Created by agibsonccc on 9/16/15.
*
* score … 誤差の取得
* output … ニューラルネットの処理結果を取得
*/
public class LenetMnistExample {
private static final Logger log = LoggerFactory.getLogger(LenetMnistExample.class);
public static void main(String[] args) throws Exception
{
// 変数定義
int nChannels = 1; // 入力画像のチャンネル数
int outputNum = 10; // 出力クラス数(0~9の10クラス)
int batchSize = 64; // バッチ(Size of each patch)
int nEpochs = 10; // 学習世代数
int iterations = 1; // 各学習世代で学習を繰り返す回数
int seed = 123;
// データ準備
log.info("Load data....");
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize,true,12345); // 学習データ。
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize,false,12345); // テストデータ。
// 畳み込みニューラルネットワークを定義
log.info("Build model....");
MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.regularization(true).l2(0.0005)
.learningRate(0.01)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS).momentum(0.9)
.list()
.layer(0, new ConvolutionLayer.Builder(5, 5)
.nIn(nChannels)
.stride(1, 1)
.nOut(20)
.activation("identity")
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(2, new ConvolutionLayer.Builder(5, 5)
.nIn(nChannels)
.stride(1, 1)
.nOut(50)
.activation("identity")
.build())
.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(4, new DenseLayer.Builder().activation("relu")
.nOut(500).build())
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation("softmax")
.build())
.backprop(true).pretrain(false);
new ConvolutionLayerSetup(builder,28,28,1);
// 畳み込みニューラルネットワークを作成
MultiLayerConfiguration conf = builder.build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
// 学習開始
log.info("Train model....");
model.setListeners(new ScoreIterationListener(1));
for( int i=0; i<nEpochs; i++ )
{
// 学習の実施(fit)
model.fit(mnistTrain);
log.info("*** Completed epoch {} ***", i);
log.info("Evaluate model....");
Evaluation eval = new Evaluation(outputNum);
while(mnistTest.hasNext())
{
DataSet ds = mnistTest.next();
INDArray output = model.output(ds.getFeatureMatrix(), false);
eval.eval(ds.getLabels(), output);
}
log.info(eval.stats());
mnistTest.reset();
}
log.info("****************Example finished********************");
// ファイル出力
File f2 = new File( "output/CNN.fdfsdf" );
ModelSerializer.writeModel( model , f2 , true );
}
}
実行結果
プロジェクト・フォルダ
┗ output
┗ CNN.fdfsdf
解説
今回は画像認識を行うため、ニューラルネットワークの種類として畳み込みニューラルネットワークを選択している。畳み込みニューラルネットワークの説明は省くが、学習の概要としては以下のようになる。
- 28x28ピクセルのMnistデータベースを利用
- 学習データ(mnistTrain)は6万個
- 学習データは64個で1つのミニバッチを構成し、ミニバッチ単位で学習を実施(計937回)
- 3を1試行と捉え、それを10回(nEpoochs回)繰り返し実施
学習完了後はファイル「output/CNN.fdfsdf」として、構築したニューラルネットワークをファイル出力している(118行目~119行目)。
■ プログラム2(画像認識GUIプログラムにおけるニューラルネットワークの利用)
プログラム1で作成したファイルを元に、GUI上で入力した文字画像を識別するプログラムを以下に示す。プログラムでは文字をマウスで描いたのちに、「parse」ボタンを押下するとニューラルネットワークで識別した数字の分類(0~9)を表す値を標準出力に出力する。
注意点としてはDeeplearning4jがJDK1.7(64bit)準拠であるのに対し、以下のプログラムではJDK 1.8(64bit)上で無理やり動作させている点である。また、JavaFXプログラムであるためライブラリの追加を行う必要もある(Eclipse上での操作としてはプロジェクト名を右クリックして『ビルドパス - ライブラリの追加』からJavaFXを選択する)。
リソース
プロジェクト・フォルダ
┗ output
┗ CNN.fdfsdf
プログラム
import java.io.File;
import java.io.IOException;
import java.nio.IntBuffer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
import javafx.application.Application;
import javafx.event.ActionEvent;
import javafx.scene.Scene;
import javafx.scene.canvas.Canvas;
import javafx.scene.canvas.GraphicsContext;
import javafx.scene.control.Button;
import javafx.scene.image.WritableImage;
import javafx.scene.image.WritablePixelFormat;
import javafx.scene.input.MouseEvent;
import javafx.scene.layout.BorderPane;
import javafx.scene.layout.Pane;
import javafx.scene.layout.VBox;
import javafx.scene.paint.Color;
import javafx.stage.Stage;
/**
* 手書き文字の認識テスト・プログラム
* @author karura
*/
public class App extends Application
{
public static void main(String[] args) {
launch(args);
}
@Override
public void start(Stage primaryStage) {
try {
// シーングラフの構成
BorderPane root = new BorderPane();
root.setCenter( createCanvas() );
// ウィンドウの表示
Scene scene = new Scene(root,100,100);
primaryStage.setScene(scene);
primaryStage.show();
} catch(Exception e) {
e.printStackTrace();
}
}
protected Pane createCanvas()
{
// 戻り値の作成
int width = 28;
int height = 28;
VBox layout = new VBox();
Canvas canvas = new Canvas( width , height );
Button btnInit = new Button( "init" );
Button btnParse= new Button( "parse" );
layout.getChildren().add( canvas );
layout.getChildren().add( btnInit );
layout.getChildren().add( btnParse );
// 初期化
GraphicsContext g = canvas.getGraphicsContext2D();
g.setFill( Color.WHITE );
g.fillRect( 0 , 0 , width , height );
// クリック押下時に描画するイベントを追加
canvas.addEventHandler( MouseEvent.ANY , e ->
{
// 描画色を宣言
Color col = null;
// 描画色を決定
switch( e.getButton() )
{
case PRIMARY : col = Color.BLACK; break;
case SECONDARY : col = Color.WHITE; break;
default : return;
}
// グラフィックス・コンテキストの取得
GraphicsContext g1 = canvas.getGraphicsContext2D();
// 押下場所の色を変更
g1.setFill( col );
g1.fillRect( e.getX() , e.getY() , 3 , 3 );
});
// ボタン押下時にキャンバスを初期化するイベントを追加
btnInit.addEventHandler( ActionEvent.ANY , e ->
{
// キャンバス初期化
GraphicsContext g2 = canvas.getGraphicsContext2D();
g2.setFill( Color.WHITE );
g2.fillRect( 0 , 0 , width , height );
});
// ボタン押下時にキャンバスの内容を解析するイベントを追加
btnParse.addEventHandler( ActionEvent.ANY , e ->
{
// 入力画像を解析する
WritableImage img = canvas.snapshot( null , null );
parse( img );
});
// 戻り値を返す
return layout;
}
protected void parse( WritableImage img )
{
// 構築済みニューラルネットワークの読込
File f = new File( "output/CNN.fdfsdf" );
MultiLayerNetwork model = null;
try {
// ファイルから読込
model = ModelSerializer.restoreMultiLayerNetwork( f );
} catch (IOException e) { e.printStackTrace(); }
// 画像を変換
WritablePixelFormat<IntBuffer> format = WritablePixelFormat.getIntArgbInstance();
int size = (int) (img.getWidth() * img.getHeight());
int[] pixels = new int[ size ];
img.getPixelReader().getPixels( 0 , 0 , (int)img.getWidth() , (int)img.getHeight() ,
format , pixels, 0 , (int)img.getWidth() );
INDArray input = Nd4j.create( 1 , size );
for( int i=0 ; i<size ; i++ )
{
// b成分のみ抽出
// 黒が透明部分、白が文字部分になるように色を反転
int pixel = 0xFF - ( pixels[ i ] & 0xFF );
input.put( 0 , i , pixel );
}
// 解析を実行
INDArray output = model.output( input , false );
System.out.println( "[output]" );
System.out.println( output );
}
}
実行結果
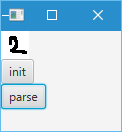
17:45:09.599 [JavaFX Application Thread] DEBUG org.nd4j.nativeblas.NativeOps - Number of threads used for linear algebra 1
…中略…
[output]
[0.00, 0.00, 1.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00]
解説
実行結果を見てみると、output配列内で値=1となっている要素のインデックスが分類値に該当するため、上記では画像を2として正しく識別していることが確認できる。何度か動作させてみると識別に失敗する場合もあるが、2~3回書き直せばだいたい正しく認識することが確認できると思われる。
プログラムの構成自体は単純で、Canvasクラス上で左ボタンを押下したままマウスを動かすと軌道上のピクセル値を変更する処理(54行目~90行目)と、parseボタン押下時にCanvasの内容を画像として取得しニューラルネットワークでの解析を行う処理が主な処理である(102行目~107行目)。
画像の解析処理を詳しく見ていくと、まずニューラルネットワークをファイルから再構築(116行目~121行目)し、画像のピクセル値をINDArrayクラスに格納(124行目~136行目)、ニューラルネットワークの入力とすることで数字の識別を行っている(139行目)。
■ 参照
- DeepLearning4j 「Convolutional Networks」