前回『
Colladaファイルビュアーを作成する(2)』に引き続き、解析用のColladaファイルを読んでいく。解析用Colladaファイルをダウンロードしていない人は前回の記事からダウンロードして頂きたい。今回は解析用Colladaファイル『luka1_0_1.dae』の読み方と、プログラムに取り込む方法を確認する。
■ Sceneノードから解析する (宣言とインスタンス化)
Colladaファイルを読む際に気をつけるのは、宣言の記述とインスタンス化の記述を分けて考えることである。プログラミングでクラスを利用する場合と同じで、クラスを宣言(定義)するだけでは描写せず、インスタンス化することで初めて描写する。宣言とインスタンス化の見分けは簡単で、『instance_*』という名前のノードがインスタンス化部分で、それ以外のノードが宣言部分である。
■ インスタンス化の流れを追う
では、実際に解析用Colladaファイルを読んでいく。Colladaファイルを人の目で見る場合はsceneノードから読み始める。sceneノードは名が示すとおり、画面出力するscene全体の情報を保持している。以下に解析用ColladaファイルのXML階層を示す。
◇解析用Colladaファイル『luka1_0_1.dae』のXML階層
 ※上記はgoogle chromeで『luka1_0_1.dae』を開き、asset~library_controllersノードを閉じた際のイメージである
※上記はgoogle chromeで『luka1_0_1.dae』を開き、asset~library_controllersノードを閉じた際のイメージである
sceneノードをみると、子要素にinstance_visual_sceneノードを呼び出している。リファレンスを見ると、instance_visual_sceneは『visual_sceneリソースのインスタンス化』を示しており、urlプロパティでインスタンス化すべきvisual_sceneのURIが指定されている。ここでいうURIはノードのIDのことである。urlプロパティでは『#Scene』と指定されている。『#』は参照先がこのファイル内であることを示すので、visual_sceneでかつID=Sceneであるノードをインスタンス化する。
続いて参照先のID=Sceneであるノードを見る。このノードは子要素を持っているため、子ノードを解析していく。上記イメージでは省略されているが、例えばID=CameraのNodeノードは下層で『instance_camera』を呼び出しているため、また他のノードのインスタンス化が行われる。このようにインスタンス化は階層を掘り下げながら再帰的に行われていき、最終的に表現したいシーン全体の情報(メッシュ情報やカメラ、照明など)がインスタンス化される。
Colladaファイルを理解するには、このインスタンス化の流れを頭の中で再現することが大切である。ちなみに、解析用Colladaファイルでは以下のようなインスタンスの構造となっている。
◇解析用Colladaファイル『luka1_0_1.dae』の解析階層(ID参照のツリー構造)
scene
┗ visual_scene( Scene )
┣ Camera(カメラのインスタンス)
┃ ┗ ・・・
┣ Hemi_000(光源のインスタンス)
┃ ┗ ・・・
┣ Hemi_003(光源のインスタンス)
┃ ┗ ・・・
┣ l_a_body(メッシュのインスタンス)
┃ ┗ ・・・
┣ l_body(メッシュのインスタンス)
┃ ┗ ・・・
┣ l_dress(メッシュのインスタンス)
┃ ┗ ・・・
┗ l_hair(メッシュのインスタンス)
┗ ・・・
■ XMLファイルをプログラムに取り込む
Colladaファイルの読み方がなんとなく分かってきたところで、プログラムに入っていく。まずは方式設計ということで、Colladaファイルをどのようにプログラム上にデータとして読み込むかを考える。ColladaファイルはXML形式で記述されているため、DOMやSAXで取り込むことが最初に思いつくが、もう少し楽ができないかと調べたところJavaではJAXBという標準パッケージがあるということなので、これを利用する。
JAXB(Java Architecture for XML Binding)は、XMLファイル⇔JavaのBeanクラス間のデータ変換を行うパッケージである。Beanクラスとはgetter/setterしか持たないデータ保持用のクラスのことである。さらに、JAXBにはXML スキーマを元にJavaのBeanクラスを自動生成する機能も付属しているので、作業の省力化が可能である。以下ではJAXBを用いて、解析用Colladaファイルの一部を解析していく。
■ JAXBでBeanクラスを自動作成する
まずは、JAXBでBeanクラスの自動生成を行う。JAXBは標準パッケージに含まれるため、新たに環境構築する必要はない。必要なのは、取り込みたいXMLファイルの構造を示したXMLスキーマである。JavaのBeanクラスを作成する手順は以下の通りである。Beadクラスの生成に成功すると同フォルダに『org』というフォルダが作成され、Beanクラスを宣言した*.javaファイルが生成されていることが確認できる。
- Collada公式サイトからXMLスキーマ( COLLADA 1.4.1 Schema (updated for microsoft XSD) )をダウンロード
- コマンドプロンプトを開いてダウンロードしたファイルと同じフォルダに移動
- コマンド「xjc collada_schema_1_4_1_ms.xsd」を実行
■ エラーが発生した場合
作業時にエラーが出る場合などは以下を参照して対処する。
◇ケース1
xjcコマンドが見つからないというメッセージが表示される場合、環境変数JAVA_HOMEがうまく設定できていない可能性がある。xjcはJavaのbinフォルダにあるプログラムなので、絶対パスで指定することで実行可能である。jdk1.8.0_60の場合はデフォルトで「C:\Program Files\Java\jdk1.8.0_60\bin\xjc.exe」にxjcプログラムが存在する。
◇ケース2
xjc実行時、以下のようなメッセージが出力される場合がある。
[ERROR] プロパティ"Source"はすでに定義されています。この競合を解決するには、<jaxb:property>を使用します。 行9129/file:/~
[ERROR] 次の場所は前述のエラーに関連しています
行9178/file:/~
[ERROR] プロパティ"Source"はすでに定義されています。この競合を解決するには、<
jaxb:property>を使用します。
行8785/file:/~
[ERROR] 次の場所は前述のエラーに関連しています
行8875/file:/~
[ERROR] プロパティ"MiOrMoOrMn"はすでに定義されています。この競合を解決するには、
<jaxb:property>を使用します。
行132/http://www.w3.org/Math/XMLSchema/mathml2/presentation/scripts.xsd
[ERROR] 次の場所は前述のエラーに関連しています
行138/http://www.w3.org/Math/XMLSchema/mathml2/presentation/scripts.xsd
スキーマの解析に失敗しました。
上記エラーが発生した場合は次の手順を実施する。詳細は『
SHIVA'S CAFE』に記述がある。
- 『Simpler and better binding mode for JAXB 2.0』の『this "schemalet"』というリンクからsimpleMode.xsdをダウンロード
- ダウンロードしたファイルを、XMLスキーマと同じフォルダに配置
- コマンドプロンプトから『xjc (XMLスキーマファイルへのパス) -extension simpleMode.xmd』を実行
■ JAXBでXMLファイルを取り込む
次に自動生成された*.javaファイルを取り込む。特別な設定は必要なく、作業スペースにorgフォルダをコピペするだけでよい。Eclipseから見ると、以下のようにパッケージとして認識される。
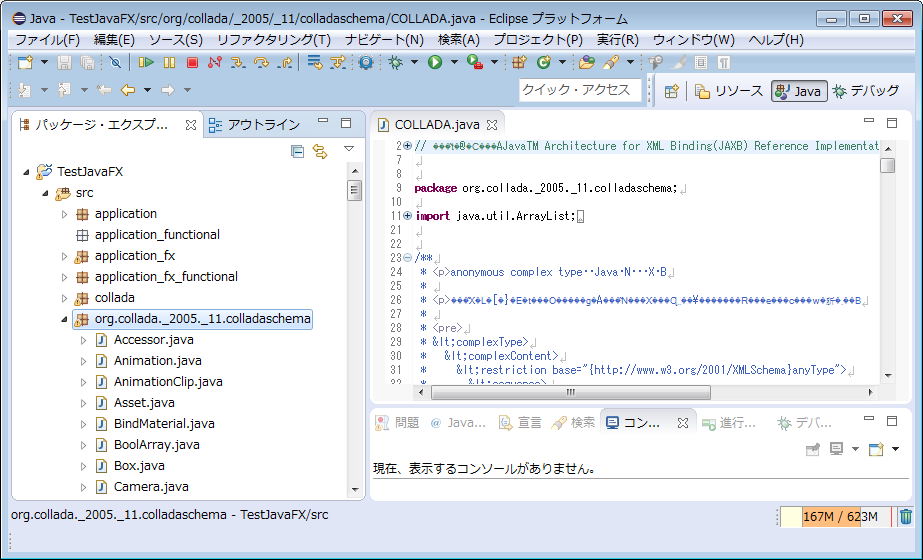
では、JAXBの使い方の確認を含めて、ColladaファイルのVisual_Sceneノードを取り込んでみる。JavaFXサンプルコードは以下の通りである。
◇サンプルコード
package collada;
import java.io.File;
import javax.xml.bind.JAXBContext;
import javax.xml.bind.JAXBException;
import javax.xml.bind.Unmarshaller;
import org.collada._2005._11.colladaschema.COLLADA;
import org.collada._2005._11.colladaschema.LibraryVisualScenes;
import org.collada._2005._11.colladaschema.Node;
import org.collada._2005._11.colladaschema.VisualScene;
public class TestCollada {
public static void main(String[] args)
{
// ファイルから読み込み
try {
// 読込パッケージを決定
String packageName = "org.collada._2005._11.colladaschema";
// XMLパーサを作成
JAXBContext jc = JAXBContext.newInstance( packageName );
Unmarshaller unmarshaller = jc.createUnmarshaller();
// JAXBを利用して、ファイルからCOLLADAインスタンスを作成
File f = new File( "3dmodel/Luka/luka1_0_1.dae" );
COLLADA collada = (COLLADA) unmarshaller.unmarshal( f );
// Collada直下Library_Visual_Sceneを取得
for( Object o : collada.getLibraryAnimationsAndLibraryAnimationClipsAndLibraryCameras() )
{
// Visual_Sceneノードであれば、処理を実行
if( ! ( o instanceof LibraryVisualScenes ) ){ continue; }
// 型変換
LibraryVisualScenes libraryVisualScenes = (LibraryVisualScenes) o;
// Library_Visual_Scenes直下のVisualSceneを取得
for( VisualScene visualScene : libraryVisualScenes.getVisualScenes() )
{
// VisualScene直下のNodeを取得
for( Node node : visualScene.getNodes() )
{
// NodeノードのIDを出力
System.out.println( node.getId() );
}
}
}
} catch (JAXBException e) {
e.printStackTrace();
}
}
}
◇実行結果
Camera
Hemi_000
Hemi_003
l_a_body
l_body
l_dress
l_hair
◇解説
- XMLファイルの読み込みのためには、まずXML解析クラスUnmarshallerを作成する(24行目~25行目)。作成時にはJAXBで自動生成したパッケージ名を指定する必要がある
- XMLデータをの取り込むには、Unmarshaller::unmarshal関数を利用する(29行目)。unmarshal関数では、XML上のルートノードに対応するデータを返す。JAXBではXML上のノード名がデータ取り込み先のBeanクラス名となっているため、戻り値はCOLLADA型になる。
- 取り込んだデータからVisualScene直下のノード一覧を取得するには、COLLADA型クラスからノード階層に対応したクラスを順次取得していく(33行目~52行目)。取得にはgetter関数が用意されている。例えばLibraryVisualScenesについて、子ノードであるVisualSceneの一覧を取得するにはgetVisualScenes関数を呼び出す(42行目)。
コードが短くなるようにforループで記述しているが、実際の利用ではノード毎に処理関数を作成することで、多少見やすいコードになるハズである。次回は、取り込んだVisual_Sceneのデータの出力についてみていく。
■ 参照
- SHIVA'S CAFE