前回『
Colladaファイルビュアーを作成する(1)』に引き続き、今回はColladaファイルをテキストファイル上で読んでみる。
■ Colladaファイルの入手
ファイルを読むにもサンプルがないとつまらないので、webで公開されているボーカロイドのデータをダウンロードしColladaに変換して利用させて頂く。変換したファイルを以下に掲載する。
◇ 解析用のColladaファイル
元データ配布サイト・・・
巡音ルカモデル Download
ライセンス ・・・
ピアプロ・キャラクター・ライセンス(PCL)
注意事項 ・・・ 拡張子「*.7z」は『
7Zip』の圧縮ファイル形式
JavaFXではマルチ・テクスチャに対応していないため、
aoテクスチャを出力していない
■ 解析用Colladaファイルの作成(変換)方法
上記Colladaファイルの作成方法を示す。上記ファイルを利用する場合は、この手順を飛ばしてよい。まずは元データ配布サイトからblender形式の3Dモデルをダウンロード。ライセンスはピアプロキャラクターライセンス(PCL)なので、制限つきで2次利用可能。ライセンスの詳細は上記リンクを参照のこと。3DモデルソフトはBlenderを利用する。インストールについて、特に問題はなかったので割愛。
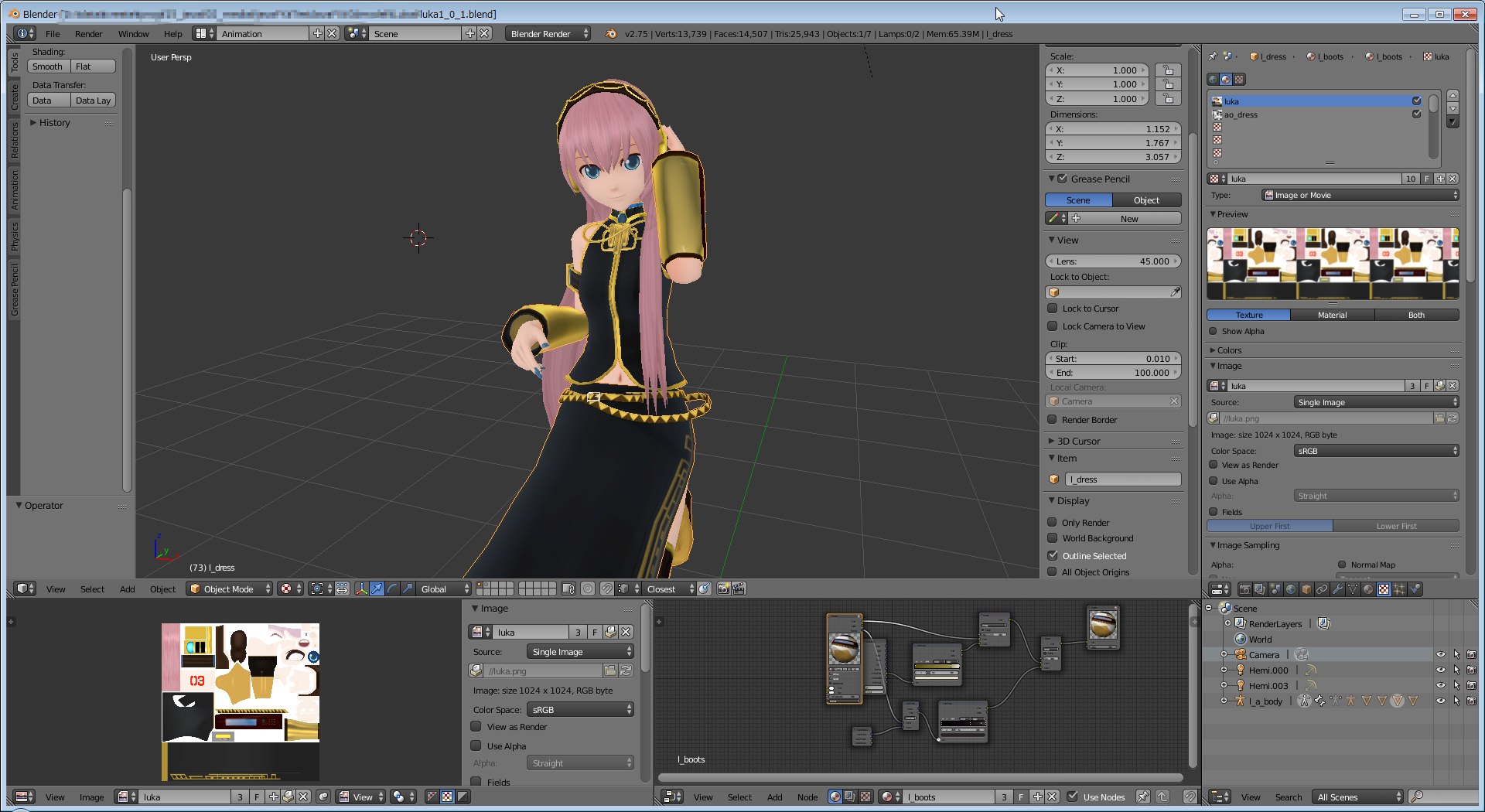
ダウンロードしたデータ(*.blend)をダブルクリックしてBlenderで開くと、上記画像のように取り込まれているのが分かる。さっそく、Colladaファイルへのエクスポートを行う。エクスポートは画面左上のメニューから「File - Export - Collada(Default)(.dae)」を選択。
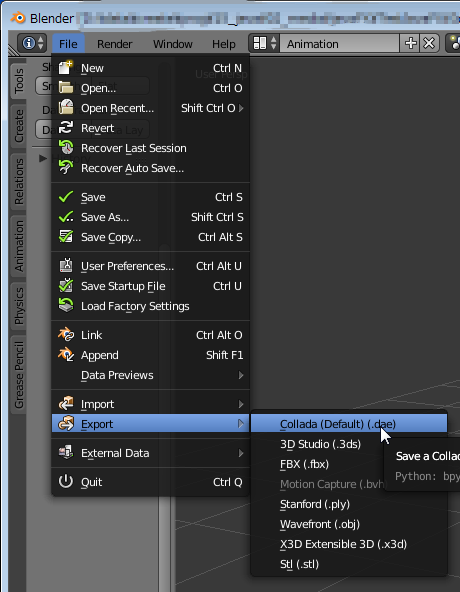
開いた画面の左下「Export COLLAD - include UV Textures」を選択。ファイルの出力パスを指定した上で、右上の「Export COLLADA」ボタンをクリック。上記画面に戻ったらエクスポートが完了している。ちなみにBlenderはなんの前触れもなく落ちることがあり、処理を待っているつもりがいつのまにかソフトが終了しているなんてことがある注意が必要。


エクスポートが完了すると、以下のように『.dae』ファイルと画像ファイルが作成される。

■ Colladaファイルの読み方
ここから先はファイル・フォーマット・ドキュメント(以下、リファレンスと表記)も参照していく。リファレンスへのリンクは以下の通り。なお、今回のBlenderのエクスポートはColladaバージョン1.4.1で行われたため、1.4.1用のリファレンスを利用。ちなみに現在のCollada最新版は1.5.0。
ページ数は多いが、読むべき部分はファイルの概要が書かれている1章~3章だけ(目次などを含めて21ページ程度)。4章以降はタグ・リファレンスである。また、ver1.4.1のリファレンスでは各所にハイパーリンクが設定されているため、クリック1つで該当ページにジャンプできるので活用する。
■ 解析用Colladaファイルを開いてみる
試しにBleanderで解析用画像『luka1_0_1.dae』を開いてみると以下のようになる。元データから多少の情報が抜け落ちている気がするがBlenderのexport/Importライブラリの話になるので気にしない。このようなモデルデータを出力することが目的だとだけ覚えておく。

ちなみに・・・
3Dモデルポーズもエクスポートしたい場合は、オプションを以下のように設定する。ただし、ジョイント(及びボーン)情報は変更されない。
→
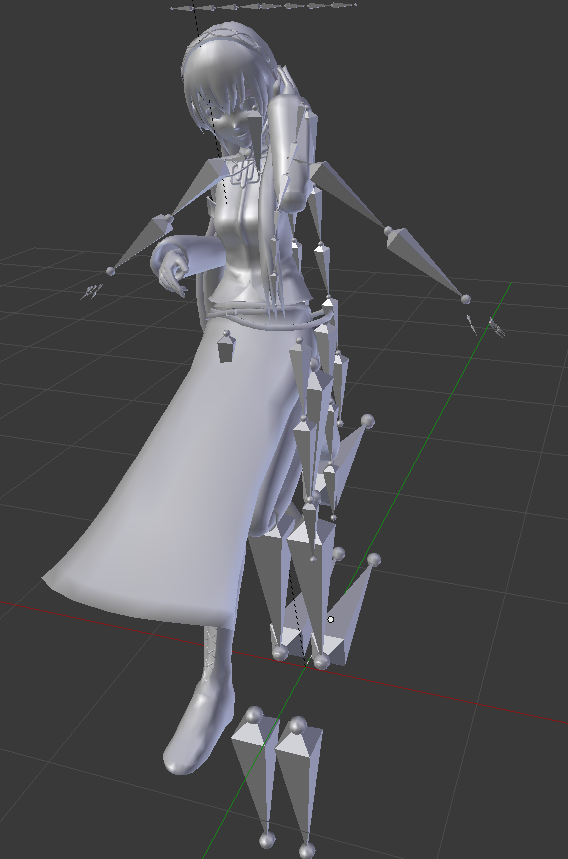
続いて、webブラウザで『luka1_0_1.dae』ファイルを開いてみる。エディタで開いてもよいが、ファイルサイズが大きいためにメモ帳などで開くとフリーズする可能性がある。開く場合は遅延リードできる『
サクラ・エディタ』等を利用する。
Colladaファイルはテキスト情報として保存されているため、大抵の方はなんとなく雰囲気で読めそうな雰囲気を感じると思う。ルートタグを見て分かるように、ColladaファイルはXMLファイルとして認識できる。

■ Colladaファイルを読む基本ルール
Colladaファイルを読む際の基本は、以下の通りである。
- ノード(開始タグと終了タグで区切られた部分)は任意のオブジェクトを表している
- ノードは宣言用ノードと、インスタンス化用ノードに分類できる
- ノードは、他ノードをIDもしくはSIDで参照できる
上記についてサンプルを用いて説明する。サンプルとして、キャラクタの髪を表すメッシュを宣言する過程を見る。キャラクタの髪を表すメッシュは、解析用ファイルの1795行目~1848行目で宣言している。説明用に一部中略すると以下のような形である。なお、これより先の説明では実際の行番号ではなく、以下の例の行番号を用いる。
<geometry id="l_hair-mesh" name="l_hair">
<mesh>
<source id="l_hair-mesh-positions">
<float_array id="l_hair-mesh-positions-array" count="3885">
0 0.1543591 3.006679
(中略)
-0.06403326 -0.09196209 3.395838</float_array>
<technique_common>
<accessor source="#l_hair-mesh-positions-array" count="1295" stride="3">
<param name="X" type="float"/>
<param name="Y" type="float"/>
<param name="Z" type="float"/>
</accessor>
</technique_common>
</source>
<source id="l_hair-mesh-normals">
(中略)
</source>
<vertices id="l_hair-mesh-vertices">
<input semantic="POSITION" source="#l_hair-mesh-positions"/>
</vertices>
<polylist material="l_hair-material" count="2557">
<input semantic="VERTEX" source="#l_hair-mesh-vertices" offset="0"/>
<input semantic="NORMAL" source="#l_hair-mesh-normals" offset="1"/>
<input semantic="TEXCOORD" source="#l_hair-mesh-map" offset="2" set="0"/>
<input semantic="COLOR" source="#l_hair-mesh-colors-Col" offset="3" set="0"/>
<vcount>3 3 3 (中略) 3 3 3 </vcount>
<p>48 0 0 (中略) 1284 7670 7670</p>
</polylist>
</mesh>
</geometry>
髪全体を現すgeometryノードはID:l_hair-meshとして宣言され、その内訳はmeshノード内に記述されている(1行目~2行目)。メッシュノード内では、float型の定数配列をsourceノードで宣言し、異なるIDで管理(3行目~20行目)。これら定数配列は続く、頂点や法線の定義で利用される。
例えば、頂点情報はverticesノードで記述し、先に宣言したsourceノードのID=l_hair-mesh-positionsを頂点の位置情報として利用することを定義している(21行目~23行目)。この際、1次元配列であるfloat_array(ID:l_hair-mesh-positions-array)内には[ X,Y,Z ]の順番で1295個の頂点情報が格納されていることが、technique_commonノード内に記述されている(8行目~14行目)。
polylistノードでは、メッシュを三角形の集合体として定義している(24行目~31行目)。三角形の集合を定義するため、多くの3Dグラフィクス・ライブラリ(OpenGLやDirectX等)でそうであるように以下のものを定義している。
- 頂点の集合。ID=l_hair-mesh-verticesの値を利用(25行目)
- 法線の集合。ID=l_hair-mesh-normalsの値を利用(26行目)
- テクスチャの集合。ID=l_hair-mesh-map-0,1の値を利用(27行目~28行目)
- 頂点色の集合。ID=l_hair-mesh-colors-Colの値を利用(29行目)
- 三角形を現す頂点・法線・テクスチャへのインデックス番号の集合(31行目)
実際に読んでみると、1つ目の三角形は( 頂点 , 法線 ,テクスチャ ) = ( 48番 , 0番 , 0番 )を利用し手いることが分かる(30行目)。頂点48番は中略していて見れないので頂点0番をみると、頂点0は( X , Y , Z ) = ( 0 , 0.1543591 , 3.006679 )となっている(5行目)。法線、テクスチャも同様にインデックス番号でたどる。
ここまでが髪の宣言である。インスタンス化はまた別のところで行っているが、説明が込み入ってくるので、次回以降に見ていく。が、簡単に言うと『すべてのインスタンス化の始まりはsceneノードであり、シーン(見えるもの全て)全体をインスタンス化する(2555行目~2557行目)箇所である。インスタンス化処理はIDをたどって再帰的に行われている』という形になる。
長くなったので、続きは次回。
改訂履歴・2015年11月 9日 一部改訂。解析用COLLADAファイルを差替
・2015年11月12日 3Dモデルのポーズ出力方法を追記