今回はディープラーニングの実装の一つとなる畳み込みニューラルネットワークを見ていく。畳み込みニューラルネットワークは主に画像認識で利用される機械学習手法である。
■ 畳み込みニューラルネットワーク(CNN)とは?
畳み込みニューラルネットワークとは、層状のニューラルネットワークであり、多層パーセプトロンにおける以下の欠点に対応したニューラルネットワークである。
図:多層パーセプトロンのイメージ
- 多層パーセプトロンでは入力が1次元であるため、画像のような2次元情報の縦方向のズレに弱い
- すべての層のニューロンが全結合(前層のニューロンすべてに対して接続する)ため、入力値の個数が多くなるにつれて計算に必要なパラメータ数が多くなりすぎる
1について10x10ピクセルの画像を例に説明する。多層パーセプトロンの入力は1次元であるため10x10の配列は100x1の1次元配列に変換する必要がある。すると画像上の座標(0,0)のピクセル値が縦に1ピクセル移動し(0,1)にずれた場合、1次元配列上では0番目の要素が10番目にずれたことになる。このずれを小さくするため畳み込みニューラルネットワークでは入力画像をreceptive fieldという小さな領域(3x3や5x5の小さな画像)に分割して、各領域にフィルタ処理やプーリングという処理を行うことで縦・横ズレに対する弱さを緩和している。
2はメモリ容量の問題やパラメータ更新の計算量の多さに加え、アルゴリズム的にも過学習が起こりやすいという問題がある。この問題に対応するためにニューロンを立体的(width,height,depthの3次元)に並べ、深さが同じニューロンのグループ(depth slice)に関しては同じパラメータ(フィルタ)を利用するという工夫を行っている。
畳み込みニューラルネットワークのイメージ
畳み込みニューラルネットワークの構成は、多層パーセプトロンの入力前に層を追加したような以下の構造を持つ。畳み込みニューラルネットワークでは層の組み立て方はさまざまであり、代表的な構成は[INPUT - CONV - POOL - CONV - POOL - RELU - OUTPUT]や[INPUT - CONV - RELU - POOL - FC - OUTPUT]のような組み立てである。
表:畳み込みニューラルネットワークで利用する層の種類
| 層の名称 |
Deeplearning4j内のクラス |
内容 |
畳み込み層
(略:CONV) |
ConvolutionLayer |
前層のreceptive fieldに対しフィルター処理(畳み込み処理)を行う |
プーリング層
(略:POOL) |
SubsamplingLayer |
前層を画像としてとらえ、大きさ(width,height)を縮小する |
全結合層
(略:FC,RELU) |
DenseLayer |
前層のニューロンに対し全結合を行う。多層パーセプトロンの層と同等の働きをする。出力の次元数は1。 |
出力層
(略:OUTPUT) |
OutputLayer |
全結合層と同様。ただし、活性化関数にソフトマックス関数を利用するなどして、出力の総和が1になるようにするなどの正規化を行う。出力の次元数は1。 |
図:畳み込みニューラルネットワークの構成イメージ
各層の次元(width,height,depth)について
畳み込みニューラルネットワークにおいては、各層のニューロンを横一列に並べるのではなく、立体的(width,height,depthの3次元)に並べている。各次元については入力層を例に考えるとわかりやすい。入力層ではwidth,heightが入力画像の幅と高さを表すのに対し、depthはある画素におけるRGB値などのチャンネルを表している。グレースケール画像であればdepth=1であるし、RGB画像であればdepth=3となる。入力層以外の層についても、前層の出力情報を画像としてとらえて処理をしていると考えると分かりやすい。
以下では、各層の処理内容について確認していく。
畳み込み層(ConvolutionLayer)
畳み込みニューラルネットワークのメイン処理を行う層である。以下で入力、出力に分けて説明する。
1.入力信号
畳み込み層への入力信号はフィルタ処理とスライド処理を交互に行いながら作成される。
フィルタ処理では前層の一部領域(receptive field)の出力に対して2次元のフィルタ(加重マップ)を掛け合わせ、その合計値を計算する。後述するストライドが(1,1)の場合、畳み込み層のニューロンn(x,y)への入力値に対しては、前層の(x,y)~(x+fx,y+fy)の位置にあるニューロンの出力値をreceptive fieldとして設定する。もし、前層のdepthが1より多い場合receptive fieldは3次元となる。フィルタ処理のイメージは以下のとおりである。
図:3x3のフィルタを用いた場合の畳み込み層の動作イメージ
上図で行われているフィルター処理を行う計算式は以下のとおりである。ただし、\(in(x,y)\)は畳み込み層のニューロン\((x,y)\)への入力、\(h(x,y,d)\)は前層のニューロン\((x,y,d)\)の出力、\(f(x,y)\)はフィルタの\((x,y)\)の値を表す。
\begin{align*}
in(x,y) & = \sum h(i,j,d)f(i,j)\\
& = \sum h(i,j,0)f(i,j) + \sum h(i,j,1)f(i,j)\\
& = ( -2 + 0 + 1 - 8 + 0 - 1 + 2 + 0 - 4 )\\
& + ( -3 + 0 + 4 - 2 + 0 + 6 - 1 + 0 + 1 )\\
& = -7
\end{align*}
フィルタは1つ以上設定することができる。また、フィルタ処理においては前層の末端(最上下段や最左右列)のニューロンの出力値の影響が小さくなってしまう。このため、パディングと呼ばれる出力値0の出力値を仮想的に作成し、末端の更に外側に配置してフィルタ処理を行うことが一般的である。
スライド処理はフィルタの位置をずらす処理のことである。ずらす位置をストライドと呼び2次元配列で表される。例えばストライドが(2,2)の場合には1度のスライド処理ではx方向に2ずらし、ストライドが(1,1)の場合には1度のスライド処理でx方向に1ずらす。スライドを繰り返して端まで言った場合には、左に戻りyの値だけ縦方向にずらして同様の処理を行う。スライド処理のイメージは以下のとおりである。
図:スライド処理の動作イメージ
CS231n(
*1)では上記で説明したフィルタ処理とスライド処理の動作を動画で確認することができるので、分かりずらい場合にはこちらで確認いただきたい。
これら入力信号の処理に関して、画像処理の観点で見てみるとぼかしや輪郭線検知などのフィルタ処理そのものの動作と等しい。このため、畳み込み層では前層で出力された画像に対して、フィルタ処理を行った新たな画像を出力する処理としてみることもできる。
2.出力信号
畳み込み層のニューロンの出力値も多層パーセプトロンと同様、活性化関数の出力値となる。
また、上記より畳み込み層のニューロンの数\(N\)は、前層のニューロン数とフィルタの数によって定義され以下の式で表される。
\begin{align*}
N_{width} & = \frac{ In_{width} - F_{width} + 2P }{S_{width}} + 1 \\
N_{height} & = \frac{ In_{height} - F_{height} + 2P }{S_{width}} + 1 \\
N_{depth} & = F_{num} \\
\end{align*}
| 変数 |
内容 |
| \(In\) |
前層ニューロンの数 |
| \(F\) |
フィルタのサイズ
\(F_{num}\)はフィルタの数を表す |
| \(P\) |
パディングのサイズ |
| \(S\) |
ストライド |
逆に言うと、これらのパラメータの値が整数にならないような設定は使用できない。そのような場合にはPを適切に設定するなどで対応する必要がある。
学習フェーズにおいては多層パーセプトロンと同様の処理でパラメータ更新を行うが、入力重みパラメータの増分\(\triangle w\)はフィルタの値に加算する。フィルタの値はすべてのニューロンで共有されているため、学習後のフィルタ値はすべてのニューロンで計算した入力重みパラメータ\(\triangle w\)が加算されることになる。
最後に畳み込み層という名前の由来に関して。畳み込みという言葉は数学で\(\sum f(x)g(x-t)\)という計算のことを指す。畳み込み層の入力処理も、前層の出力\(f(x)\)に対してフィルタ\(g(x-t)\)を乗算し合計しているとみることができるため、この名前が付いたと考えられる。が、利用の際にはあまり覚えておかなくてもよいと思われる。
プーリングレイヤー(POOL)
プーリングレイヤーは前層の出力値を削減する層である。画像処理でいうところの縮小処理に当たる。最も一般的な縮小方法は、前層のある範囲で最も大きな値をニューロンの出力とする方法である。プーリングレイヤーの動作イメージを以下に示す。
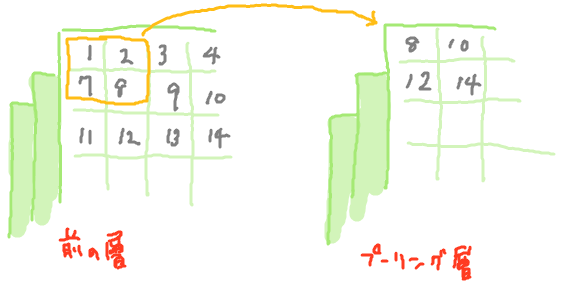 図:プーリング層の動作イメージ
図:プーリング層の動作イメージ
上記ではフィルターサイズ2x2、ストライド(2,2)で処理を行っている。4つの入力に対して1つの出力となるため、ニューロンの出力値を75%節減することになる。画像処理的な目で見ると隣あう4pixelを1pixelに縮小することに相当する。入力と出力を比較すると、widthとheightの数は縮小されるがdepthは等しいままである。
縮小処理については昔は平均をとるという手法が主流であったが、現在はでは最大値を利用する方法が主流である。学習(誤差逆伝搬法)を行う際には、最大値を出力したニューロンにだけ誤差を伝搬させるという処理になる。最近のトレンドとして、ニューロン数の削減にはプーリングレイヤーをはさむのではなく、畳み込み層のストライドを大きくする事が好まれているという話もある。
全結合層
多層パーセプトロンの層と同様の処理を行う層である。すなわち、前層すべてのニューロンの出力値の重み付き合計値を入力として受け取り、活性化関数の出力値を出力するという層である。活性化関数に\(f(x)=max(0,x)\)を利用した全結合層を特にRELU層と呼んでいる模様である。
■ 畳み込みニューラルネットワーク構成上の注意点
以下の注意点はCS231n(
*1)にて記述された内容である。
1つ目はフィルタサイズについてで、フィルタの大きさは小さいほうが表現力が高いということらしい。また、大きなフィルタを1つ持つより、小さなフィルタを複数持つ持つ方が必要なパラメータ数も小さいため、フィルタサイズは小さくフィルタ数を大きく設定するようにしたほうがいいようである。一般的なフィルタサイズは3x3や5x5で、最初の畳み込み層であればフィルタサイズ7x7でもよい結果が得られる可能性があるとのこと。
2つ目は畳み込み層の入力数はできるだけ2の倍数に設定するべきである点である。これは入出力の次元数を考慮してのことと思われる。
3つ目はプーリング層の縮小の設定についてで、フィルタサイズ2x2/ストライド=(2,2)か、フィルタサイズ=3x3/ストライド=(2,2)程度にしておくべきとのことである。縮小処理のフィルタサイズにより縦横のずれに対する許容性が生まれるが、一方でフィルタサイズを大きすぎると情報のロスが大きくなりすぎてしまうということのようである。
4つ目はパディングは積極的に利用すべきということで、これは末端ニューロンの情報を有効活用するためである。
■ サンプルプログラム
以下にDeeplearning 4jで畳み込みニューラルネットワークを実装するサンプルプログラムを示す。サンプルプログラムはDeeplearning 4jの公式web上のサンプルであり、Mnistデータベースに格納された手書き数字(0~9)で学習し、手書き数字の認識を行う畳み込みニューラルネットワークである。サンプルプログラムの実行時間はマシンスペックにもよるが、2時間程度はかかるものと思われる。
プログラム
package org.deeplearning4j.examples.convolution;
import org.deeplearning4j.datasets.iterator.impl.MnistDataSetIterator;
import org.deeplearning4j.eval.Evaluation;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
//import org.deeplearning4j.nn.conf.LearningRatePolicy;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.conf.layers.setup.ConvolutionLayerSetup;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Created by agibsonccc on 9/16/15.
*/
public class LenetMnistExample {
private static final Logger log = LoggerFactory.getLogger(LenetMnistExample.class);
public static void main(String[] args) throws Exception {
int nChannels = 1;
int outputNum = 10;
int batchSize = 64;
int nEpochs = 10;
int iterations = 1;
int seed = 123;
log.info("Load data....");
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize,true,12345);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize,false,12345);
log.info("Build model....");
MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.regularization(true).l2(0.0005)
.learningRate(0.01)//.biasLearningRate(0.02)
//.learningRateDecayPolicy(LearningRatePolicy.Inverse).lrPolicyDecayRate(0.001).lrPolicyPower(0.75)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS).momentum(0.9)
.list()
.layer(0, new ConvolutionLayer.Builder(5, 5)
.nIn(nChannels)
.stride(1, 1)
.nOut(20)
.activation("identity")
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(2, new ConvolutionLayer.Builder(5, 5)
.nIn(nChannels)
.stride(1, 1)
.nOut(50)
.activation("identity")
.build())
.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(4, new DenseLayer.Builder().activation("relu")
.nOut(500).build())
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation("softmax")
.build())
.backprop(true).pretrain(false);
new ConvolutionLayerSetup(builder,28,28,1);
MultiLayerConfiguration conf = builder.build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
log.info("Train model....");
model.setListeners(new ScoreIterationListener(1));
for( int i=0; i<nEpochs; i++ ) {
model.fit(mnistTrain);
log.info("*** Completed epoch {} ***", i);
log.info("Evaluate model....");
Evaluation eval = new Evaluation(outputNum);
while(mnistTest.hasNext()){
DataSet ds = mnistTest.next();
INDArray output = model.output(ds.getFeatureMatrix(), false);
eval.eval(ds.getLabels(), output);
}
log.info(eval.stats());
mnistTest.reset();
}
log.info("****************Example finished********************");
}
}
実行結果
19:06:10.904 [main] INFO LenetMnistExample - Load data....
19:06:16.289 [main] INFO LenetMnistExample - Build model....
19:06:27.122 [main] DEBUG org.nd4j.nativeblas.NativeOps - Number of threads used for linear algebra 1
19:06:27.122 [main] DEBUG org.nd4j.nativeblas.NativeOps - N
…中略…
19:19:51.393 [main] INFO LenetMnistExample - *** Completed epoch 0 ***
19:19:51.393 [main] INFO LenetMnistExample - Evaluate model....
19:20:52.961 [main] INFO LenetMnistExample -
Examples labeled as 0 classified by model as 0: 971 times
Examples labeled as 0 classified by model as 1: 1 times
Examples labeled as 0 classified by model as 2: 2 times
Examples labeled as 0 classified by model as 6: 4 times
Examples labeled as 0 classified by model as 7: 2 times
Examples labeled as 1 classified by model as 1: 1124 times
…中略…
==========================Scores========================================
Accuracy: 0.979
Precision: 0.9789
Recall: 0.9789
F1 Score: 0.9789
========================================================================
…略
解説
32行目~41行目では学習用のMnistデータを取得している。Mnistデータの詳細については
別記事を参照していただきたいが、データの内容については文字が描かれた28x28ピクセルの画像を6万個用意しているとだけ理解していただければよい。
43行目~81行目では、畳み込みニューラルネットワークを定義している。45行目~52行目がニューラルネットワーク全体の設定で、層の定義は53行目~79行目となる。このニューラルネットワークを図示すると以下のような構造になっている。
図:定義したニューラルネットワークのイメージ
入力層については定義に含めないので、0層目として畳み込み層が定義されている(54行目~59行目)。活性化関数は恒等関数、フィルタサイズは5x5、フィルタ数は20、ストライド=(1,1)で設定している。
1層目はプーリング層で最大値を取得するマックス・プーリングを利用している。フィルタサイズは2x2、ストライド=(2,2)として設定。2層目・3層目では、畳み込み層とプーリング層をさらにはさみ、4層目で全結合層(RELU)をニューロン数500で定義している。
最後に5層目で出力層を定義している。活性化関数はソフトマックス関数、誤差関数は負の対数尤度関数、出力数は10としている。ソフトマックス関数を利用しているためすべての出力値の合計は1となり、出力値=確率としてみることができる。
83行目~85行目は上記の定義をもとに、畳み込みニューラルネットワークのインスタンスを定義している。90行目~103行目では学習(MultiLayerNetwork::fit関数)と、出力(MultiLayerNetwork::output関数)、評価(Evaluation::eval関数)をの実行を1世代の処理として、10世代分処理を繰り返している。出力と評価では学習とは別のデータ(mnistTest変数)を利用しており、学習したものだけでなく一般的な手書き数字の認識を行っていることが分かる(108行目~110行目)。
実行結果を見ていくと1世代目の結果は、0が描かれた画像を正しく0と認識した回数が971回、1と誤認識した回数が1回、2と誤認識した回数が2回、6と誤認識した回数が4回、7と誤認識した回数が2回と概ね識別に成功している。全体の正解率も98%程度と高い水準で畳み込みニューラルネットワークが構築できていることが確認できる。
■ 参照
- CS231n Convolutional Neural Networks for Visual Recognition「Convolutional Neural Networks (CNNs / ConvNets)」
- Deeplearning4j 公式 「 Convolutional Networks in Java」